目前,ChatGPT等大型AI算法的出现对计算设备性能提出了更高要求。存内计算(CIM)有效缓解了传统冯诺依曼架构中的内存墙问题。尽管无法完全解决存储墙问题,但CIM架构通过定制化设计方法将存储单元和计算电路结合在一起,本质上提高了操作数的传输带宽,大大降低了这部分数据的传输代价。近年来,许多具有高计算能效的数字CIM架构处理器的工作被提出。这些工作通过定制化设计数据路径控制微架构和稀疏优化微架构,能够在计算不同类型的主流AI算法(如CNN、Transformer)时实现很高的计算能效。然而CIM架构的计算特点是多个周期得到MAC计算结果,不能像传统数字电路一样在流水线填充后每个周期都能得到MAC计算结果。这使得CIM架构的应用场景被限制在边缘端的低功耗场景,而非高性能场景。如何在保持CIM计算架构高能效的同时解决其吞吐率不足的缺点是CIM架构成为AI计算领域通用架构路上的关键问题。
针对该关键问题,中国科学院微电子研究所刘明院士/张锋研究员团队研发出基于Radix16+LUT技术的SRAM存内计算处理器芯片。该工作分别在电路级、微架构级和数据级三个层面提出了通用的性能优化技术,在保持CIM架构高计算能效的同时,提高了其在通用AI计算领域的的吞吐率。
在电路层面,团队使用Radix16+LUT的技术将INT8*INT8的计算周期数量降低到2,首次实现了该数据精度下的2周期计算(之前最好记录是4周期);使用LUT技术尽可能降低其中权重编码电路的动态功耗开销,使得单周期内的电路计算功耗降低了21.7%,最终实现了1.84-2.44倍的MAC计算功耗降低和2-4倍的吞吐率提升。
在微架构层面,团队提出了可配置Winograd/Spatial混合数据路径微架构和像素/通道混合映射方法。使用训练的方法决定在算法的每一层使用哪种等级的Winograd算法实现计算吞吐率的提升。在算法workload映射上,为了在保持高并行度的同时增加硬件利用率,处理器结合像素/通道混合映射方法在intra-macro使用通道顺序映射;在inter-macro使用像素顺序映射。最终,该项技术在算法准确率损失小于2.2%的同时帮助处理器取得了2.59倍的吞吐率提升。
在数据层面,团队充分调研了近几年稀疏优化技术的代表性工作并分类总结,在这些工作的基础上提出了macro级并行稀疏优化策略。对于激活数据稀疏以每个macro的输入数据为一组,以组为单位使用检测-跳过的方式挑选出能够被跳过的稀疏数据实现稀疏激活数据优化。对于权重数据使用水平方向紧凑排列的方式将权重数据向水平方向压缩,从而实现稀疏权重数据的计算跳过。计算出的结果数据根据激活数据检测索引和权重数据索引在输出结果寄存器中重新排列为稀疏跳过操作之前的数据格式。且为了减少因为稀疏优化导致的计算停顿,在interval-cycle处理部分稀疏数据以实现latency hiding。该项稀疏优化技术解决了以往该领域类似技术中计算并行度受限、对权重数据格式有特殊要求和稀疏策略通用性不够高(如需要重新训练的结构化稀疏)的问题,是一种通用的稀疏优化策略,最终帮助处理器提升了3.11倍的计算吞吐率。
上述设计在28nm 工艺上得到验证,在提出的三种技术支持下实现了最高258.5TOPS/W的峰值计算能效。相比已有的state-of-the-art CIM处理器工作其标准化计算吞吐率提升了2.04-3.05倍,计算能效提升了2.55-3.45倍。该工作使用分层解耦合的思想在电路、微架构和数据三个层面充分探索其设计空间,针对CIM架构处理器分别提出了通用的吞吐率优化技术。这一研究结果为通用目的的高性能CiM架构处理器设计提供了新思路。
上述研究成果以题为“A 28-nm 19.9-to-258.5-TOPS/W 8b Digital Computing-in-Memory Processor With Two-Cycle Macro Featuring Winograd-Domain Convolution and Macro-Level Parallel Dual-Side Sparsity”发表在集成电路设计领域旗舰期刊IEEE Journal of Solid-State Circuits上,微电子所博士研究生吴昊为第一作者,微电子所张锋研究员与清华大学陈勇教授为通讯作者。该研究得到了科技部重点研发计划、国家自然科学基金、中国科学院战略先导专项等项目的支持。
全文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10562243
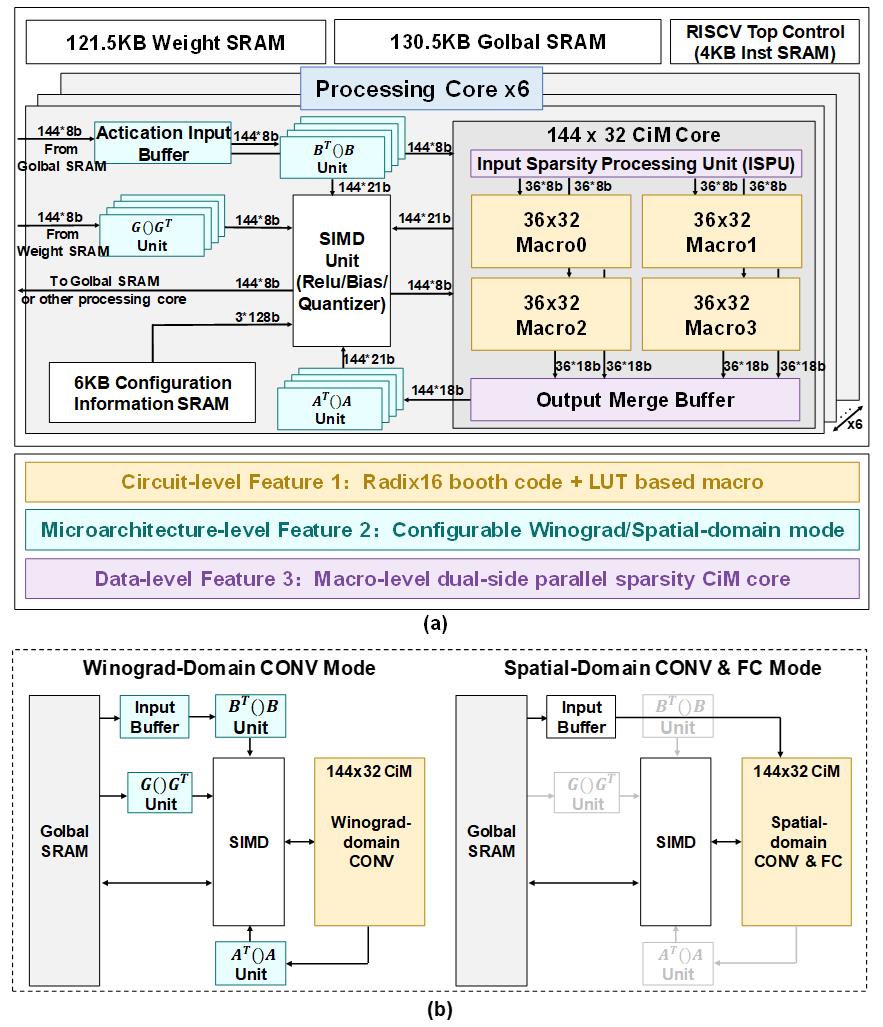
图1 (a) 处理器整体架构图 ,(b) 两种工作模式的数据流向
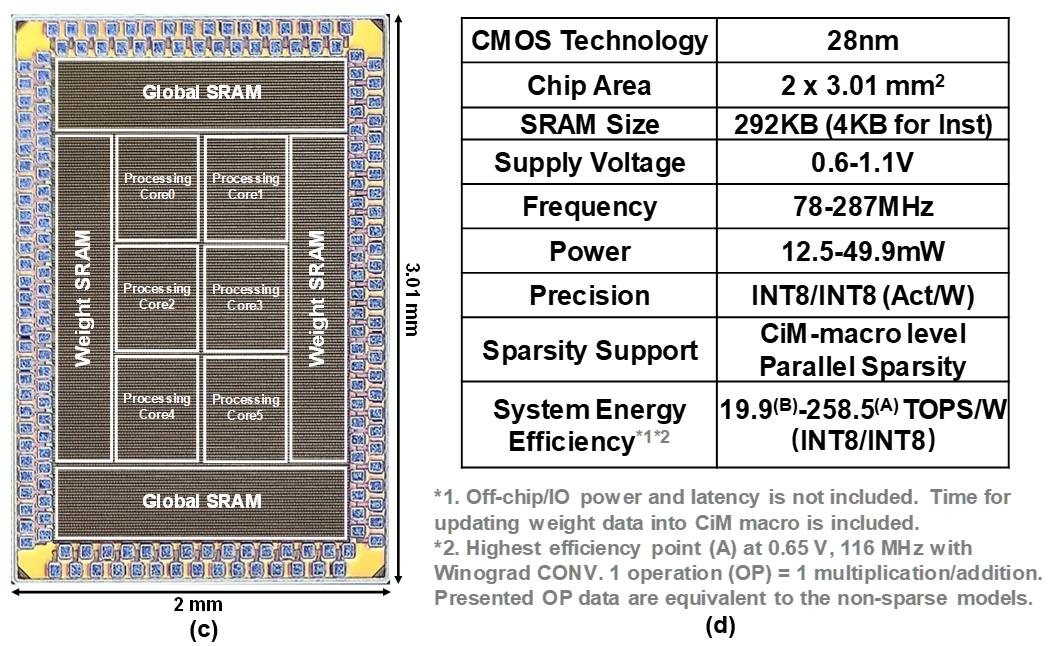
图2 (c) 芯片die photo ,(d) 总结表格
科研工作