脉冲神经网络(SNNs)具有事件驱动、低能耗的特性,非常适合在自动驾驶、移动医疗等边缘计算场景中部署。在现实应用中,由于用户数据存在场景偏差,预训练的 SNN 模型往往难以直接适配个性化任务。尽管设备端训练被视为一种可行的解决路径,但在资源有限的边缘硬件上实现高效率、低功耗的训练,仍面临显著挑战。
针对上述问题,中国科学院微电子研究所集成电路制造技术全国重点实验室研究团队,通过算法与硬件协同设计,在小批次学习场景下实现了边缘端脉冲神经网络的高能效训练。团队提出了一种硬件友好的训练算法——脉冲直连反馈对齐(SDFA),在误差反向传播过程中构建了直连反馈路径,其中反馈权重采用全随机矩阵,且在训练过程中保持固定,无需更新,大幅降低了计算与存储开销。在硬件层面,团队设计了名为 PipeSDFA 的高效忆阻存内计算架构,充分利用 SDFA 的算法特性,实现了时间步、数据与批处理的三级流水线并行处理。该架构还借助忆阻器件的本征随机性,高效存储固定的随机反馈矩阵。为进一步提升计算能效,团队引入了输入数据复用机制,并提出了高效权重映射方案(vw-SDK),有效优化了计算资源的利用。实验结果表明,SDFA 算法在多个数据集上保持了与基线方法相当的模型精度,损失不超过 2%。在硬件效能方面,PipeSDFA 架构相比已有的 RRAM-CIM 架构(如 PipeLayer),计算速度提升1.1~10.5倍,能效比提升 1.37~2.1倍。这一研究结果有效解决了边缘设备训练中的硬件效率瓶颈,为神经形态计算系统在资源受限环境中的实际应用提供了可扩展的解决方案。
此项研究结果以 “When Pipelined In-Memory Accelerators Meet Spiking Direct Feedback Alignment: A Co-Design for Neuromorphic Edge Computing”为题在德国慕尼黑举办的第44届国际计算机辅助设计会议(ICCAD)上进行了口头报告。微电子所硕士研究生任浩雄为第一作者,微电子所尚大山研究员为通讯作者。该工作得到了国家重点研发计划、国家自然科学基金和中国科学院的支持。
国际计算机辅助设计会议ICCAD(IEEE/ACM International Conference on Computer-Aided Design)由美国计算机协会(ACM)和电气与电子工程师协会(IEEE)联合主办,是全球电子设计自动化(EDA)与集成电路设计领域历史悠久、影响力深远的顶级学术会议之一。会议聚焦芯片设计自动化、存内计算、AI 架构等前沿方向,吸引了全球顶尖科研团队与半导体企业的广泛关注。
文章链接:https://doi.org/10.1109/ICCAD66269.2025.11240745
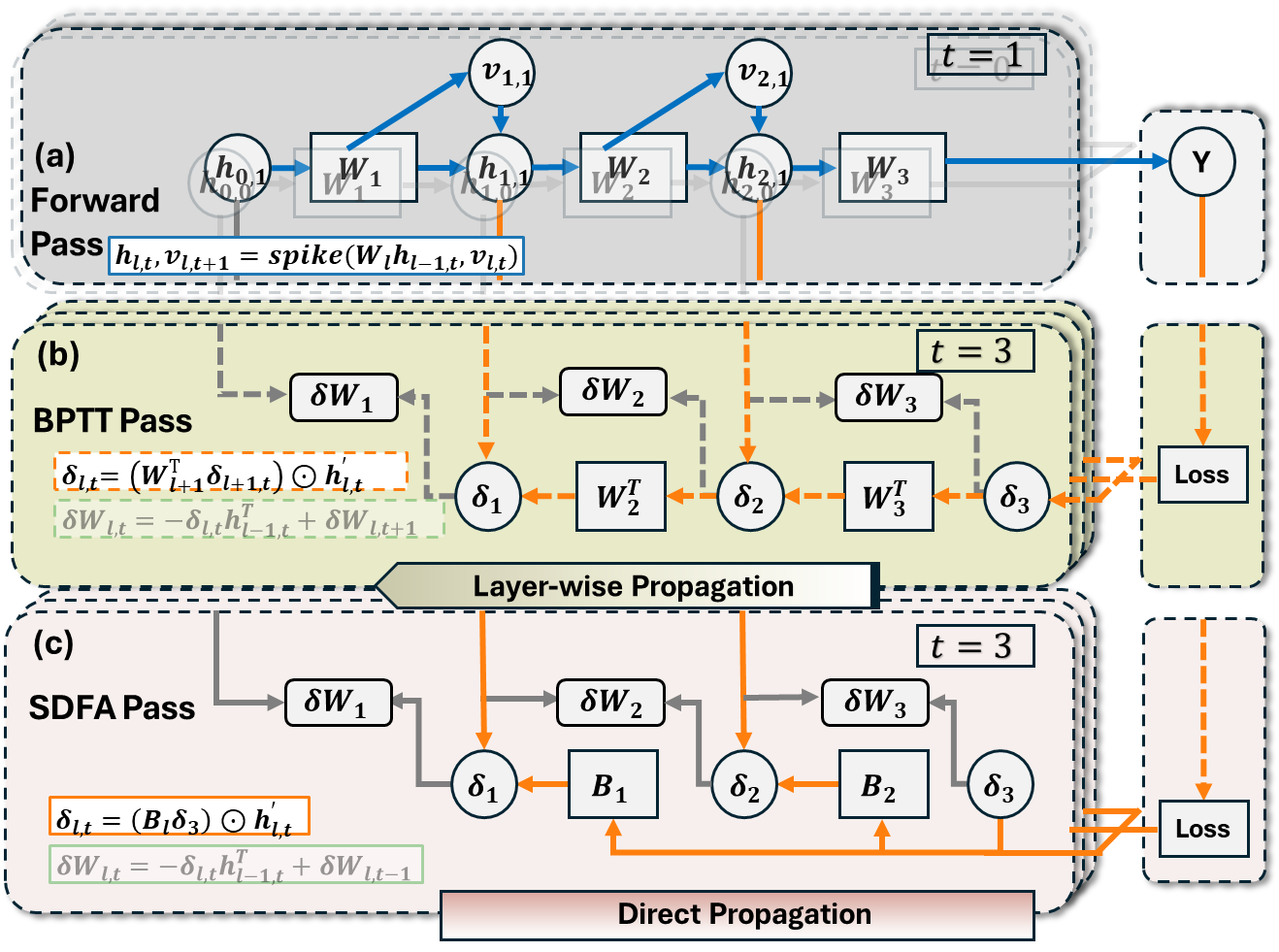
图1 脉冲直连反馈对齐算法(SDFA)流程图
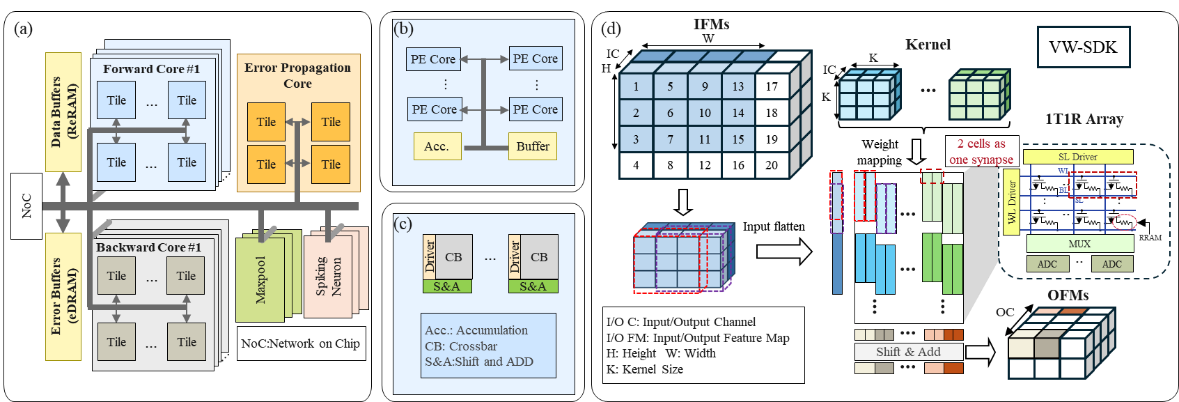
图2 存内计算架构
综合信息